Over the last year we’ve updated our autocompletes to improve how they work and address usability issues we’ve found. We’ve tried to make these improvements general purpose so that other teams can benefit from them.
For most projects you should be able to ‘drop-in’ our new code. You can add extra configuration with data attributes, or leave as is to get better results sorted in a more useful way.
Problems we’re trying to overcome
Filtering available items
The autocomplete takes your search query and looks for an exact match in the available entries. This excludes close matches or ones where there’s an extra word or punctuation in between.
For example, these searches will fail:
| Search term | Should match but gets missed |
|---|---|
| Bachelor art | Bachelor of art |
| dh law | D.H. Lawrence Studies |
| Bedfordshire university | University of Bedfordshire |
| The University of Bedfordshire | University of Bedfordshire |
For each of these examples, the search term gives us enough information to know what the user meant, but the filtering algorithm is too strict.
Sorting filtered results
The autocomplete does not sort results. It returns results ordered in the same order as the source data. If the source data was alphabetical, then the results will be too. This means that more likely matches may appear some way down the list.
Although alphabetical may seem natural, users tend to expect that autocompletes will return relevant results first. This is particularly important when there are lots of results. If what the user has typed exactly matches an option, it would be sensible for that option to be suggested first.
Support for synonyms
The default sorting algorithm uses the list of items with no in-built support for synonyms. If we know users refer to the same thing by two different names, we should aim to recognise both of those.
These would benefit from having synonyms added:
| Search term | Should match but gets missed |
|---|---|
| Maths | Mathematics |
| Masters | Master of… |
Our revised algorithm
Matching each word in the query
Matches on each word of the search query — all words are required to match, but the order does not matter.

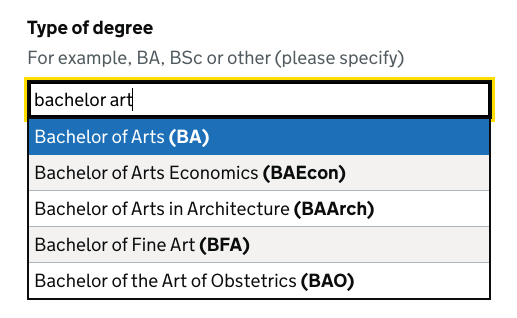
Prioritising closer matches
Results are sorted with closer matches at the top — an exact match will be first, followed by matches against the name and then matches against the synonym.
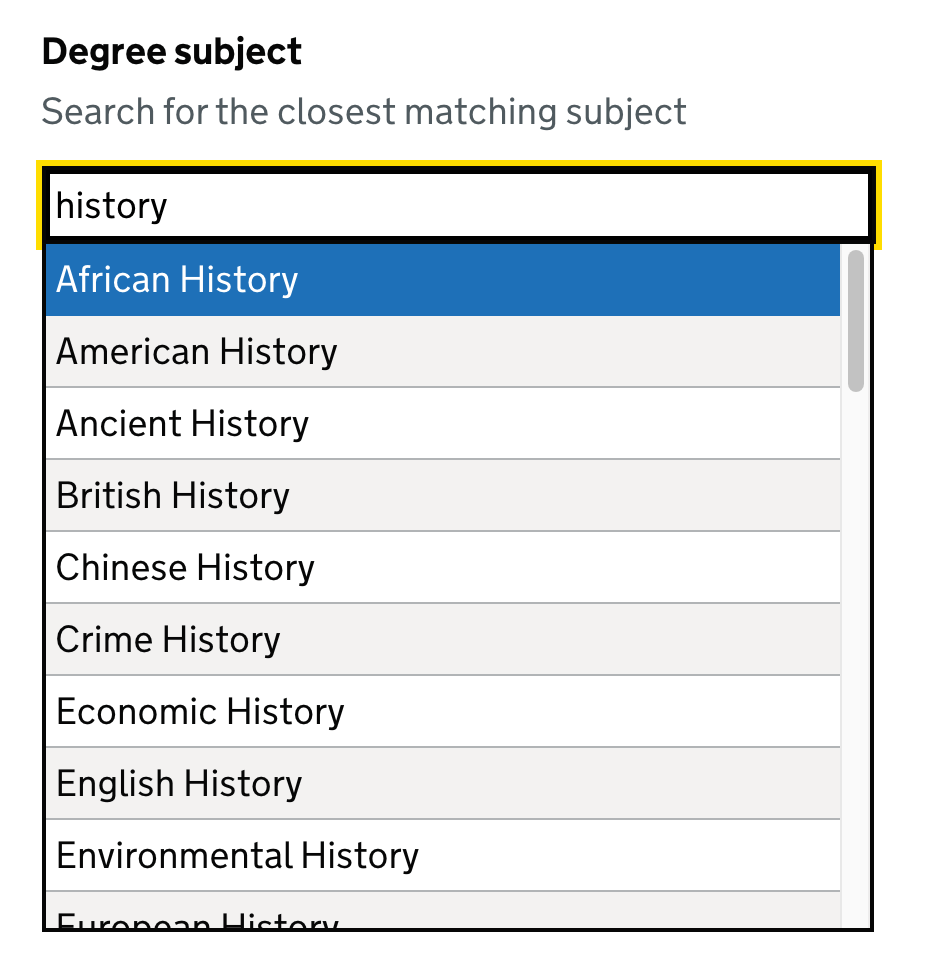
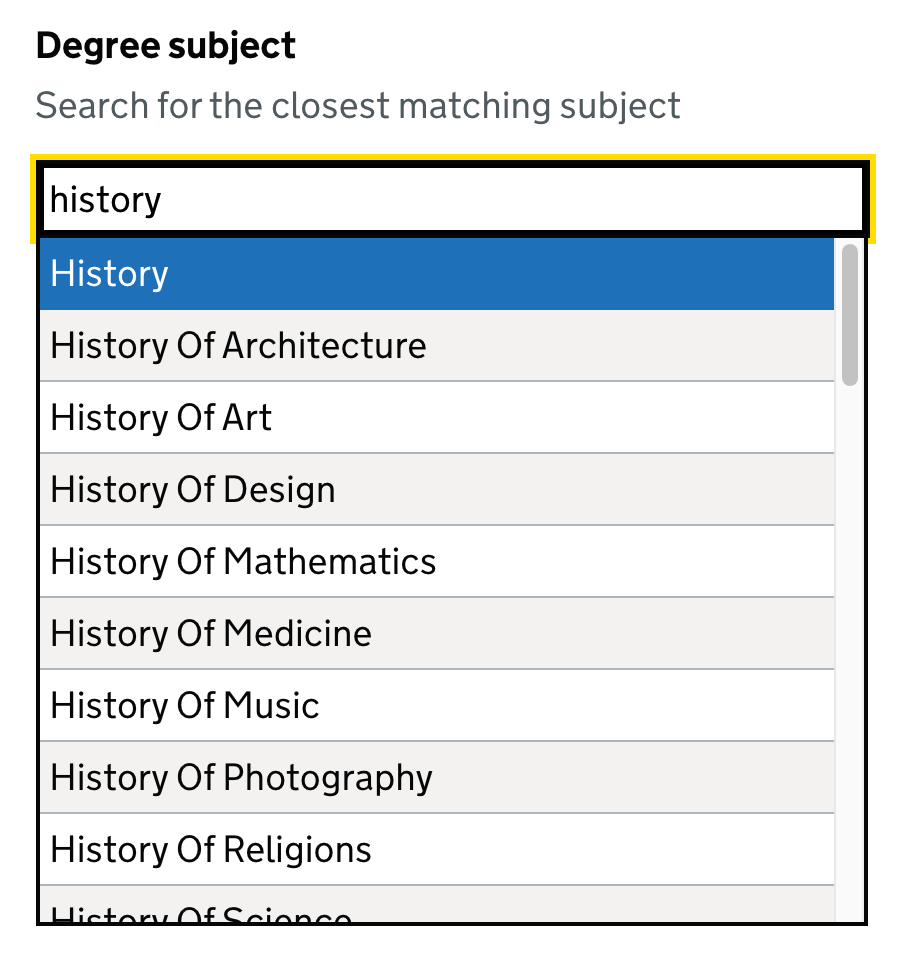
Punctuation-less searching
Searches without punctuation so it does not matter if a user types master’s or masters.
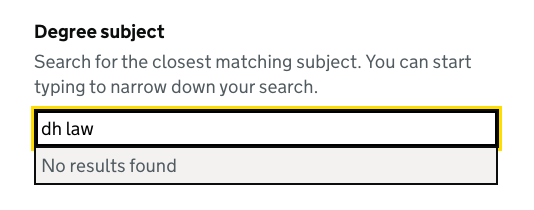
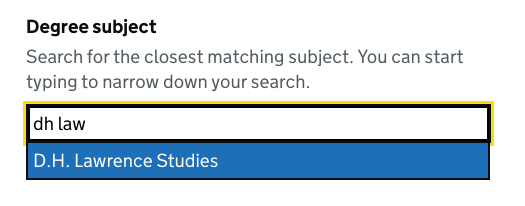
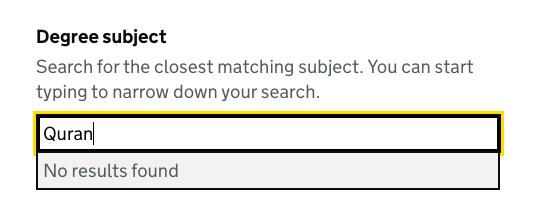
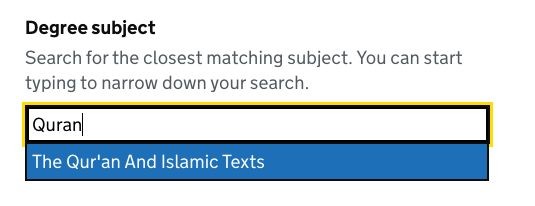
Matching with synonyms
We’ve added support for synonyms so related words can also be searched — maths and mathematics will both work. These can be added with data attributes.

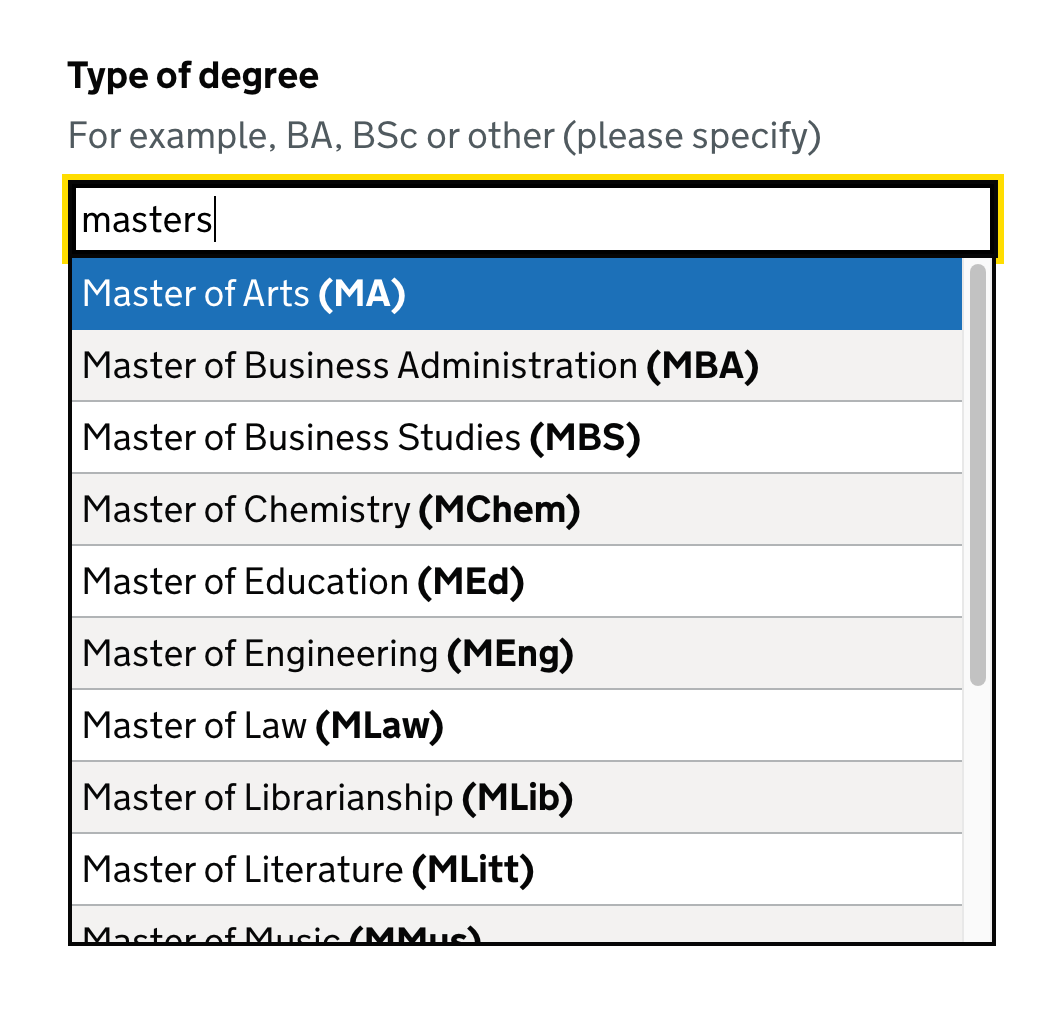
Boosting specific items
Individual items can be boosted if they’re common. A service could use these to tune the autocomplete so the most popular options are more likely to be sorted to the top. In Register we’ve boosted the degree types Bachelor of Arts and Bachelor of Science as they’re by far the most common.
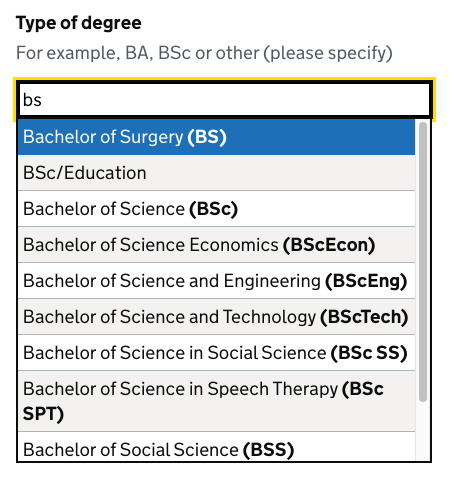
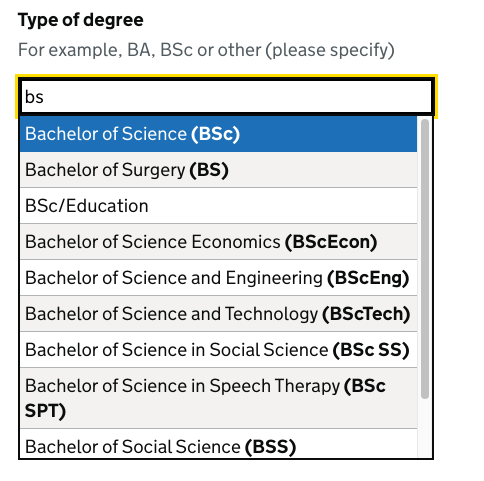
Ignoring stop words
Queries including stop words (the, of, in, and, at, &) will work whether or not the user uses them, and regardless of if the matched item’s name has a stop word.
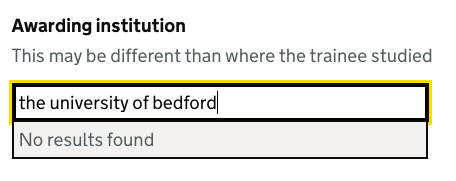
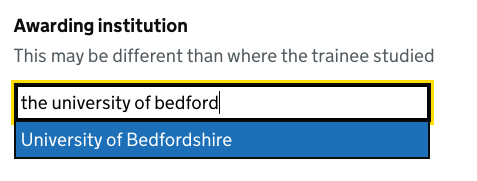
Appending more information
Individual items can have the data attribute data-append to specify content to be shown at the end of the item. We use this to show the degree type abbreviation in bold.
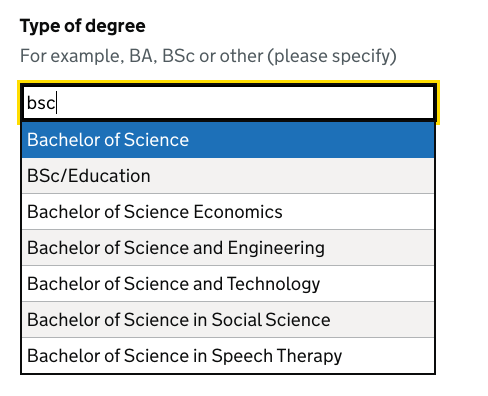
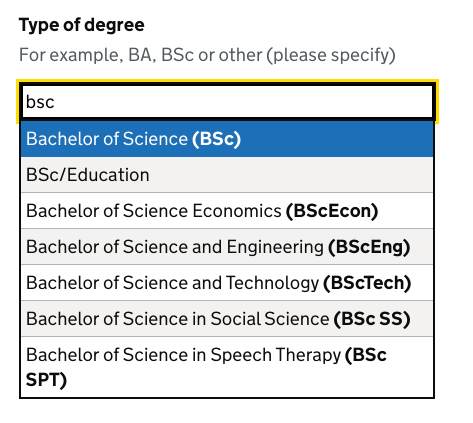
Showing hints
Individual items can have a data attribute data-hint that provides more information to display visually on the next line.


Work for teams to do
Much of the improvements teams can expect to see depend on them optimising it by providing suitable synonyms and boosting likely results. We’ve learned a lot about what users are likely to type in to our autocompletes by watching users use them in user research, analysing free text responses from Apply, and by adding analytics to our autocompletes to see where users are struggling.
Find the code
The various bits of code for these improvements can be found: